Setting up a Multi-Node Hadoop Cluster with Docker:
Using a Self-Built Image from Apache Hadoop Repository.
A Guide to Building a Multi-Node Hadoop Cluster with Docker Compose.
Welcome to this comprehensive guide. We will walk through the process of setting up a multi-node Hadoop cluster using Docker Compose. This approach allows us to containerize the entire Hadoop ecosystem, significantly simplifying deployment, scaling, and management.
The Advantage of a Custom Docker Image
Instead of relying on pre-built images from Docker Hub (such as apache/hadoop:3.4.2), we will construct a custom Hadoop image from the ground up using a Dockerfile. Building on a base image like ubuntu:22.04 offers key benefits:
- Full Control & Transparency: You have complete oversight of the image's contents, dependencies, and configuration.
- Reproducibility: Ensure a consistent and predictable environment every time the image is built.
- Enhanced Security: Mitigate risks by starting with a trusted base image and explicitly defining each layer.
- Customization: Tailor the environment to your project's specific requirements without being constrained by a generic image.
Architecture Overview
The cluster we will build consists of the following core components distributed across multiple containers:
- HDFS (Hadoop Distributed File System): For distributed storage.
- YARN (Yet Another Resource Negotiator): For resource management and job scheduling.
- Master Node: Hosting the NameNode (HDFS master) and ResourceManager (YARN master).
- Worker Nodes: Running DataNodes (HDFS workers) and NodeManagers (YARN workers).
In the following sections, we will meticulously go through each step:
- Crafting a Dockerfile to build our custom Hadoop image.
- Configuring the docker-compose.yml file to define the multi-node cluster topology.
- Deploying and managing the cluster with Docker Compose commands.
- Validating the cluster's health and functionality.
Steps to Create a Hadoop Image with Dockerfile
-
Choose a base image.
Typically, you start with a lightweight Linux distribution like:- ubuntu:22.04
- debian:bullseye
- centos:7 (older but often used in Hadoop setups)
-
Install Dependencies.
Hadoop requires:- Java (OpenJDK 8 or 11, depending on version)
- SSH & rsync (needed for Hadoop daemons communication)
- Common Linux utilities
-
Download & Extract Hadoop.
- Fetch the binary tarball (hadoop-3.4.2.tar.gz) from the Apache mirror.
- Extract it into a directory (e.g., /opt/hadoop).
- Configure environment variables (HADOOP_HOME, JAVA_HOME, PATH).
-
Add Configuration Files
- Copy core-site.xml, hdfs-site.xml, yarn-site.xml, and mapred-site.xml from your host into the container (if you want pre-configured Hadoop).
- Or leave defaults and mount configs at runtime.
-
Setup SSH (for multi-node simulation).
- Configure passwordless SSH inside the container (used by Hadoop scripts like start-dfs.sh and start-yarn.sh).
-
Define Entrypoint / CMD
- Decide if the container should run a single daemon (namenode, datanode, resourcemanager, nodemanager) or an all-in-one pseudo-distributed node.
- Use CMD/ENTRYPOINT to run the chosen Hadoop service.
Our Cluster Architecture:
-
HDFS: 1 NameNode + 3 DataNodes (replication factor: 3)
- datanode1
- datanode2
- datanode3
-
YARN: 1 ResourceManager + 3 NodeManagers
- nodemanager1
- nodemanager2
- nodemanager3
- HistoryServer: Job history and timeline services
- Docker Network: Custom bridge network for service discovery
Step 1: Setting up the project structure.
First, create a directory structure for the project.
hadoop
├── config
│ ├── capacity-scheduler.xml
│ ├── core-site.xml
│ ├── hdfs-site.xml
│ ├── log4j.properties
│ ├── mapred-site.xml
│ ├── workers
│ └── yarn-site.xml
├── docker-compose.yaml
└── Dockerfile
2 directories, 9 files
Step 2. Preparation of files of hadoop and config folders.
1. Copy the following codes and paste them into the core-site.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
<description>Where HDFS NameNode can be found on the network</description>
</property>
</configuration>
2. Copy the following codes and paste them into the hdfs-site.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop-data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop-data/datanode</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
<!-- Optional: Add these for better multi-node performance -->
<property>
<name>dfs.blocksize</name>
<value>134217728</value> <!-- 128MB -->
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>10</value>
</property>
</configuration>
3. Copy the following codes and paste them into the yarn-site.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- ResourceManager Configuration -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>resourcemanager</value>
<description>ResourceManager hostname</description>
</property>
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
<description>Bind address for ResourceManager</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>resourcemanager:8032</value>
<description>ResourceManager client address</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>resourcemanager:8030</value>
<description>Scheduler address</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>resourcemanager:8031</value>
<description>Resource tracker address</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>0.0.0.0:8088</value>
<description>ResourceManager web UI address</description>
</property>
<!-- ResourceManager High Availability -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<description>Enable RM state recovery</description>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value>
<description>RM state store implementation</description>
</property>
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>hdfs://namenode:8020/rmstate</value>
<description>HDFS path for RM state storage</description>
</property>
<!-- Scheduler Configuration -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
<description>Scheduler class</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-allocation-mb</name>
<value>8192</value>
<description>Maximum memory allocation per container</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-allocation-vcores</name>
<value>4</value>
<description>Maximum vcores allocation per container</description>
</property>
<!-- NodeManager Configuration -->
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
<description>Bind address for NodeManager</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
<description>Total memory available on NodeManager</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>8</value>
<description>Total vcores available on NodeManager</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service for MapReduce</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<description>Shuffle handler class</description>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>98.5</value>
<description>Maximum disk utilization percentage</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/app-logs</value>
<description>Directory for application logs</description>
</property>
<!-- Log Aggregation -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Enable log aggregation</description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://historyserver:8188/applicationhistory/logs/</value>
<description>URL for log server</description>
</property>
<!-- Timeline Service -->
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
<description>Enable timeline service</description>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
<description>Enable application history</description>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>historyserver</value>
<description>Timeline service hostname</description>
</property>
<property>
<name>yarn.timeline-service.bind-host</name>
<value>0.0.0.0</value>
<description>Timeline service bind address</description>
</property>
<!-- MapReduce Compression -->
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
<description>Compress map output</description>
</property>
<property>
<name>mapred.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
<description>Compression codec for map output</description>
</property>
<!-- System Metrics -->
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
<description>Enable system metrics publishing</description>
</property>
</configuration>
4. Copy the following codes and paste them into the mapred-site.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>
How hadoop execute the job, use yarn to execute the job
</description>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>8192</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx3072m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx6144m</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop/</value>
<description>
Environment variable where MapReduce job will be processed
</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop/</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop/</value>
</property>
<!-- Allow multihomed network for security, availability and performance-->
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
</configuration>
5. Copy the following codes and paste them into the capacity-scheduler-site.xml file.
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
<description>The queues at the root level</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>100</value>
<description>Default queue capacity</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>Default user limit factor</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>Default maximum capacity</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>Default queue state</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>ACL for submitting applications</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>ACL for administering queue</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>Number of missed scheduling opportunities</description>
</property>
<property>
<name>yarn.scheduler.capacity.rack-locality-additional-delay</name>
<value>-1</value>
<description>Additional delay for rack locality</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>Resource calculator implementation</description>
</property>
</configuration>
6. Copy the following codes and paste them into the log4j.properties file.
# Define some default values that can be overridden by system properties
hadoop.root.logger=INFO,console
hadoop.log.dir=.
hadoop.log.file=hadoop.log
# Define the root logger to the system property "hadoop.root.logger".
log4j.rootLogger=${hadoop.root.logger}, EventCounter
# Logging Threshold
log4j.threshold=ALL
# Null Appender
log4j.appender.NullAppender=org.apache.log4j.varia.NullAppender
hadoop.log.maxfilesize=256MB
hadoop.log.maxbackupindex=20
log4j.appender.RFA=org.apache.log4j.RollingFileAppender
log4j.appender.RFA.File=${hadoop.log.dir}/${hadoop.log.file}
log4j.appender.RFA.MaxFileSize=${hadoop.log.maxfilesize}
log4j.appender.RFA.MaxBackupIndex=${hadoop.log.maxbackupindex}
log4j.appender.RFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
log4j.appender.DRFA=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFA.File=${hadoop.log.dir}/${hadoop.log.file}
# Rollover at midnight
log4j.appender.DRFA.DatePattern=.yyyy-MM-dd
log4j.appender.DRFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
#log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.TLA=org.apache.hadoop.mapred.TaskLogAppender
log4j.appender.TLA.layout=org.apache.log4j.PatternLayout
log4j.appender.TLA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
hadoop.security.logger=INFO,NullAppender
hadoop.security.log.maxfilesize=256MB
hadoop.security.log.maxbackupindex=20
log4j.category.SecurityLogger=${hadoop.security.logger}
hadoop.security.log.file=SecurityAuth-${user.name}.audit
log4j.appender.RFAS=org.apache.log4j.RollingFileAppender
log4j.appender.RFAS.File=${hadoop.log.dir}/${hadoop.security.log.file}
log4j.appender.RFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.RFAS.MaxFileSize=${hadoop.security.log.maxfilesize}
log4j.appender.RFAS.MaxBackupIndex=${hadoop.security.log.maxbackupindex}
log4j.appender.DRFAS=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFAS.File=${hadoop.log.dir}/${hadoop.security.log.file}
log4j.appender.DRFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.DRFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.DRFAS.DatePattern=.yyyy-MM-dd
hdfs.audit.logger=INFO,NullAppender
hdfs.audit.log.maxfilesize=256MB
hdfs.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=${hdfs.audit.logger}
log4j.additivity.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=false
log4j.appender.RFAAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.RFAAUDIT.File=${hadoop.log.dir}/hdfs-audit.log
log4j.appender.RFAAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.RFAAUDIT.MaxFileSize=${hdfs.audit.log.maxfilesize}
log4j.appender.RFAAUDIT.MaxBackupIndex=${hdfs.audit.log.maxbackupindex}
namenode.metrics.logger=INFO,NullAppender
log4j.logger.NameNodeMetricsLog=${namenode.metrics.logger}
log4j.additivity.NameNodeMetricsLog=false
log4j.appender.NNMETRICSRFA=org.apache.log4j.RollingFileAppender
log4j.appender.NNMETRICSRFA.File=${hadoop.log.dir}/namenode-metrics.log
log4j.appender.NNMETRICSRFA.layout=org.apache.log4j.PatternLayout
log4j.appender.NNMETRICSRFA.layout.ConversionPattern=%d{ISO8601} %m%n
log4j.appender.NNMETRICSRFA.MaxBackupIndex=1
log4j.appender.NNMETRICSRFA.MaxFileSize=64MB
datanode.metrics.logger=INFO,NullAppender
log4j.logger.DataNodeMetricsLog=${datanode.metrics.logger}
log4j.additivity.DataNodeMetricsLog=false
log4j.appender.DNMETRICSRFA=org.apache.log4j.RollingFileAppender
log4j.appender.DNMETRICSRFA.File=${hadoop.log.dir}/datanode-metrics.log
log4j.appender.DNMETRICSRFA.layout=org.apache.log4j.PatternLayout
log4j.appender.DNMETRICSRFA.layout.ConversionPattern=%d{ISO8601} %m%n
log4j.appender.DNMETRICSRFA.MaxBackupIndex=1
log4j.appender.DNMETRICSRFA.MaxFileSize=64MB
#log4j.logger.com.amazonaws=ERROR
log4j.logger.com.amazonaws.http.AmazonHttpClient=ERROR
#log4j.logger.org.apache.hadoop.fs.s3a.S3AFileSystem=WARN
# Event Counter Appender
# Sends counts of logging messages at different severity levels to Hadoop Metrics.
#
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
# Set the ResourceManager summary log filename
yarn.server.resourcemanager.appsummary.log.file=rm-appsummary.log
# Set the ResourceManager summary log level and appender
yarn.server.resourcemanager.appsummary.logger=${hadoop.root.logger}
#yarn.server.resourcemanager.appsummary.logger=INFO,RMSUMMARY
# To enable AppSummaryLogging for the RM,
log4j.logger.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=${yarn.server.resourcemanager.appsummary.logger}
log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=false
log4j.appender.RMSUMMARY=org.apache.log4j.RollingFileAppender
log4j.appender.RMSUMMARY.File=${hadoop.log.dir}/${yarn.server.resourcemanager.appsummary.log.file}
log4j.appender.RMSUMMARY.MaxFileSize=256MB
log4j.appender.RMSUMMARY.MaxBackupIndex=20
log4j.appender.RMSUMMARY.layout=org.apache.log4j.PatternLayout
log4j.appender.RMSUMMARY.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
# YARN ResourceManager audit logging
rm.audit.logger=INFO,NullAppender
rm.audit.log.maxfilesize=256MB
rm.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.yarn.server.resourcemanager.RMAuditLogger=${rm.audit.logger}
log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager.RMAuditLogger=false
log4j.appender.RMAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.RMAUDIT.File=${hadoop.log.dir}/rm-audit.log
log4j.appender.RMAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.RMAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.RMAUDIT.MaxFileSize=${rm.audit.log.maxfilesize}
log4j.appender.RMAUDIT.MaxBackupIndex=${rm.audit.log.maxbackupindex}
# YARN NodeManager audit logging
#
nm.audit.logger=INFO,NullAppender
nm.audit.log.maxfilesize=256MB
nm.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.yarn.server.nodemanager.NMAuditLogger=${nm.audit.logger}
log4j.additivity.org.apache.hadoop.yarn.server.nodemanager.NMAuditLogger=false
log4j.appender.NMAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.NMAUDIT.File=${hadoop.log.dir}/nm-audit.log
log4j.appender.NMAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.NMAUDIT.layout.ConversionPattern=%d{ISO8601}%p %c{2}: %m%n
log4j.appender.NMAUDIT.MaxFileSize=${nm.audit.log.maxfilesize}
log4j.appender.NMAUDIT.MaxBackupIndex=${nm.audit.log.maxbackupindex}
# Appender for viewing information for errors and warnings
yarn.ewma.cleanupInterval=300
yarn.ewma.messageAgeLimitSeconds=86400
yarn.ewma.maxUniqueMessages=250
log4j.appender.EWMA=org.apache.hadoop.yarn.util.Log4jWarningErrorMetricsAppender
log4j.appender.EWMA.cleanupInterval=${yarn.ewma.cleanupInterval}
log4j.appender.EWMA.messageAgeLimitSeconds=${yarn.ewma.messageAgeLimitSeconds}
log4j.appender.EWMA.maxUniqueMessages=${yarn.ewma.maxUniqueMessages}
log4j.logger.org.apache.commons.beanutils=WARN
7. Copy the following codes and paste them into the workers file.
datanode1
datanode2
datanode3
nodemanager1
nodemanager2
nodemanager3
1. Copy the following codes and paste them into the Dockerfile file.
FROM ubuntu:22.04
# Set environment variables
ENV JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
ENV HADOOP_VERSION=3.3.6
ENV HADOOP_HOME=/opt/hadoop
ENV HADOOP_CONF_DIR=/etc/hadoop
ENV HADOOP_LOG_DIR=/var/log/hadoop
ENV HADOOP_DATA_DIR=/hadoop-data
ENV USER=hduser
ENV GROUP=hadoop
ENV PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH
# Install dependencies and create user
RUN apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get install -y \
openjdk-11-jdk \
ssh \
rsync \
wget \
vim \
openssh-server \
net-tools \
iputils-ping \
dnsutils \
sudo \
procps \
netcat-openbsd && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# Create Hadoop user and group
RUN groupadd $GROUP && \
useradd -m -g $GROUP -s /bin/bash $USER && \
echo "$USER:hduser123" | chpasswd && \
usermod -aG sudo $USER && \
echo "$USER ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
# Download and extract Hadoop as root
RUN wget https://archive.apache.org/dist/hadoop/common/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz -P /tmp && \
tar -xvzf /tmp/hadoop-${HADOOP_VERSION}.tar.gz -C /opt && \
mv /opt/hadoop-${HADOOP_VERSION} $HADOOP_HOME && \
rm /tmp/hadoop-${HADOOP_VERSION}.tar.gz
# Create necessary directories
RUN mkdir -p $HADOOP_LOG_DIR && \
mkdir -p $HADOOP_DATA_DIR && \
mkdir -p $HADOOP_CONF_DIR && \
mkdir -p /home/$USER/.ssh
# Change ownership to hduser
RUN chown -R $USER:$GROUP $HADOOP_HOME && \
chown -R $USER:$GROUP $HADOOP_LOG_DIR && \
chown -R $USER:$GROUP $HADOOP_DATA_DIR && \
chown -R $USER:$GROUP /home/$USER
# Switch to hduser for configuration
USER $USER
WORKDIR /home/$USER
# Configure SSH for Hadoop user
RUN ssh-keygen -t rsa -P '' -f /home/$USER/.ssh/id_rsa && \
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys && \
chmod 0600 /home/$USER/.ssh/authorized_keys
# Create SSH config to avoid host key verification
RUN echo "Host *" >> /home/$USER/.ssh/config && \
echo " StrictHostKeyChecking no" >> /home/$USER/.ssh/config && \
echo " UserKnownHostsFile /dev/null" >> /home/$USER/.ssh/config
# Copy Hadoop configuration files (as root temporarily)
USER root
COPY config/* $HADOOP_CONF_DIR/
RUN chown -R $USER:$GROUP $HADOOP_CONF_DIR
# Set proper permissions for Hadoop directories
RUN chmod -R 755 $HADOOP_HOME && \
chmod -R 755 $HADOOP_CONF_DIR && \
chmod -R 755 $HADOOP_LOG_DIR && \
chmod 755 $HADOOP_DATA_DIR
# Configure SSH daemon
RUN mkdir -p /run/sshd && \
echo 'PermitRootLogin no' >> /etc/ssh/sshd_config && \
echo 'PasswordAuthentication yes' >> /etc/ssh/sshd_config && \
echo 'PubkeyAuthentication yes' >> /etc/ssh/sshd_config && \
echo "AllowUsers $USER" >> /etc/ssh/sshd_config
# Create Hadoop environment script
RUN echo "export JAVA_HOME=$JAVA_HOME" >> /home/$USER/.bashrc && \
echo "export HADOOP_HOME=$HADOOP_HOME" >> /home/$USER/.bashrc && \
echo "export HADOOP_CONF_DIR=$HADOOP_CONF_DIR" >> /home/$USER/.bashrc && \
echo "export PATH=$PATH" >> /home/$USER/.bashrc && \
chown $USER:$GROUP /home/$USER/.bashrc
# Create Hadoop data directories
RUN mkdir -p $HADOOP_DATA_DIR/namenode && \
mkdir -p $HADOOP_DATA_DIR/datanode && \
mkdir -p $HADOOP_DATA_DIR/tmp && \
chown -R $USER:$GROUP $HADOOP_DATA_DIR
# Switch back to hduser
USER $USER
WORKDIR /home/$USER
# Expose Hadoop ports
EXPOSE 22 9870 9864 8088 19888 8042 9000
# Default command - start SSH daemon
CMD ["sudo", "/usr/sbin/sshd", "-D"]
2. Copy the following codes and paste them into the docker-compose.yaml file.
services:
namenode:
build: .
container_name: namenode
hostname: namenode
ports:
- "9870:9870"
- "8020:8020"
volumes:
- namenode_data:/hadoop-data/namenode
networks:
hadoop-net:
aliases:
- namenode
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/hdfs namenode -format -force &&
/opt/hadoop/bin/hdfs namenode
"
datanode1:
build: .
container_name: datanode1
hostname: datanode1
ports:
- "9864:9864"
volumes:
- datanode1_data:/hadoop-data/datanode
depends_on:
- namenode
networks:
hadoop-net:
aliases:
- datanode1
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/hdfs datanode
"
datanode2:
build: .
container_name: datanode2
hostname: datanode2
ports:
- "9865:9864"
volumes:
- datanode2_data:/hadoop-data/datanode
depends_on:
- namenode
networks:
hadoop-net:
aliases:
- datanode2
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/hdfs datanode
"
datanode3:
build: .
container_name: datanode3
hostname: datanode3
ports:
- "9866:9864"
volumes:
- datanode3_data:/hadoop-data/datanode
depends_on:
- namenode
networks:
hadoop-net:
aliases:
- datanode3
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/hdfs datanode
"
resourcemanager:
build: .
container_name: resourcemanager
hostname: resourcemanager
ports:
- "8088:8088"
- "8030:8030"
- "8031:8031"
- "8032:8032"
- "8033:8033"
depends_on:
- namenode
networks:
hadoop-net:
aliases:
- resourcemanager
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/yarn resourcemanager
"
nodemanager1:
build: .
container_name: nodemanager1
hostname: nodemanager1
ports:
- "8042:8042"
depends_on:
- resourcemanager
networks:
hadoop-net:
aliases:
- nodemanager1
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/yarn nodemanager
"
nodemanager2:
build: .
container_name: nodemanager2
hostname: nodemanager2
ports:
- "8043:8042"
depends_on:
- resourcemanager
networks:
hadoop-net:
aliases:
- nodemanager2
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/yarn nodemanager
"
nodemanager3:
build: .
container_name: nodemanager3
hostname: nodemanager3
ports:
- "8044:8042"
depends_on:
- resourcemanager
networks:
hadoop-net:
aliases:
- nodemanager3
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/yarn nodemanager
"
historyserver:
build: .
container_name: historyserver
hostname: historyserver
ports:
- "8188:19888"
depends_on:
- resourcemanager
networks:
hadoop-net:
aliases:
- historyserver
command: >
bash -c "
mkdir -p /opt/hadoop/logs &&
/opt/hadoop/bin/mapred historyserver
"
volumes:
namenode_data:
datanode1_data:
datanode2_data:
datanode3_data:
networks:
hadoop-net:
driver: bridge
name: hadoop-cluster-net
3: Build the docker image
Building a docker image can take time. The commad for creating the image looks lile the following.
docker build -t hadoop-base:3.3.6 .
Expected Outputs:
hadoop$ docker build -t hadoop-base:3.3.6 .
[+] Building 6.4s (21/21) FINISHED docker:default
=> [internal] load build definition from Dockerfile 0.2s
=> => transferring dockerfile: 3.60kB 0.0s
=> [internal] load metadata for docker.io/library/ubuntu:22.04 3.2s
=> [internal] load .dockerignore 0.2s
=> => transferring context: 2B 0.0s
=> [ 1/16] FROM docker.io/library/ubuntu:22.04@sha256:09506232a8004baa32c47d68f1e5c307d648fdd59f5e7e 1.0s
=> => resolve docker.io/library/ubuntu:22.04@sha256:09506232a8004baa32c47d68f1e5c307d648fdd59f5e7eaa 1.0s
=> [internal] load build context 0.2s
=> => transferring context: 315B 0.0s
=> CACHED [ 2/16] RUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y op 0.0s
=> CACHED [ 3/16] RUN groupadd hadoop && useradd -m -g hadoop -s /bin/bash hduser && echo "h 0.0s
=> CACHED [ 4/16] RUN wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.t 0.0s
=> CACHED [ 5/16] RUN mkdir -p /var/log/hadoop && mkdir -p /hadoop-data && mkdir -p /etc/had 0.0s
=> CACHED [ 6/16] RUN chown -R hduser:hadoop /opt/hadoop && chown -R hduser:hadoop /var/log/hado 0.0s
=> CACHED [ 7/16] WORKDIR /home/hduser 0.0s
=> CACHED [ 8/16] RUN ssh-keygen -t rsa -P '' -f /home/hduser/.ssh/id_rsa && cat /home/hduser/.s 0.0s
=> CACHED [ 9/16] RUN echo "Host *" >> /home/hduser/.ssh/config && echo " StrictHostKeyChecki 0.0s
=> CACHED [10/16] COPY config/* /etc/hadoop/ 0.0s
=> CACHED [11/16] RUN chown -R hduser:hadoop /etc/hadoop 0.0s
=> CACHED [12/16] RUN chmod -R 755 /opt/hadoop && chmod -R 755 /etc/hadoop && chmod -R 755 / 0.0s
=> CACHED [13/16] RUN mkdir -p /run/sshd && echo 'PermitRootLogin no' >> /etc/ssh/sshd_config && 0.0s
=> CACHED [14/16] RUN echo "export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64" >> /home/hduser/.ba 0.0s
=> CACHED [15/16] RUN mkdir -p /hadoop-data/namenode && mkdir -p /hadoop-data/datanode && mk 0.0s
=> CACHED [16/16] WORKDIR /home/hduser 0.0s
=> exporting to image 0.3s
=> => exporting layers 0.0s
=> => writing image sha256:45c8c303fa2d0454c5461dba3d4275539b8e1046234c026c8a38e1031df8d1e2 0.1s
=> => naming to docker.io/library/hadoop-base:3.3.6
4: Run the docker containers
Now, run the docker containers using docker-compose.
docker compose up -d
You should see these services getting started and the following outputs:
hadoop$ docker compose up -d
[+] Building 21.4s (39/39) FINISHED
=> [internal] load local bake definitions 0.0s
=> => reading from stdin 2.50kB 0.0s
=> [datanode1 internal] load build definition from Dockerfile 0.2s
=> => transferring dockerfile: 3.60kB 0.0s
.
.
.
.
.
[+] Running 22/23 Built 0.0s
✔ resourcemanager Built 0.0s
[+] Running 23/23 Built 0.0s
✔ resourcemanager Built 0.0s
✔ datanode3 Built 0.0s
✔ nodemanager2 Built 0.0s
✔ namenode Built 0.0s
✔ datanode1 Built 0.0s
✔ historyserver Built 0.0s
✔ datanode2 Built 0.0s
✔ nodemanager1 Built 0.0s
✔ nodemanager3 Built 0.0s
✔ Network hadoop-cluster-net Created 0.4s
✔ Volume "hadoop_datanode1_data" Created 0.1s
✔ Volume "hadoop_datanode3_data" Created 0.1s
✔ Volume "hadoop_namenode_data" Created 0.1s
✔ Volume "hadoop_datanode2_data" Created 0.1s
✔ Container namenode Started 6.7s
✔ Container datanode3 Started 8.7s
✔ Container datanode2 Started 8.2s
✔ Container datanode1 Started 7.3s
✔ Container resourcemanager Started 9.1s
✔ Container nodemanager1 Started 9.4s
✔ Container nodemanager2 Started 10.8s
✔ Container historyserver Started 10.4s
✔ Container nodemanager3 Started
5: Accessing the Cluster.
Login into a node:
Can login into any node by specifying the container like:
docker exec -it namenode /bin/bash
To enter the namenode, type commands that look like the following.
~/hadoop$ docker exec -it namenode /bin/bash
Expected Output:
hadoop$ docker exec -it namenode /bin/bash
To run a command as administrator (user "root"), use "sudo
hduser@namenode:~$
Running an example Job(Pi job)
hduser@namenode:~$ yarn jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 10 15
The output should look like:
Number of Maps = 10
Samples per Map = 15
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
2025-10-04 04:51:12,597 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at resourcemanager/172.18.0.6:8032
2025-10-04 04:51:12,718 INFO client.AHSProxy: Connecting to Application History server at historyserver/172.18.0.9:10200
2025-10-04 04:51:12,891 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hduser/.staging/job_1759553191529_0001
2025-10-04 04:51:13,113 INFO input.FileInputFormat: Total input files to process : 10
2025-10-04 04:51:13,239 INFO mapreduce.JobSubmitter: number of splits:10
2025-10-04 04:51:13,438 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1759553191529_0001
2025-10-04 04:51:13,438 INFO mapreduce.JobSubmitter: Executing with tokens: []
2025-10-04 04:51:13,588 INFO conf.Configuration: resource-types.xml not found
2025-10-04 04:51:13,589 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2025-10-04 04:51:13,976 INFO impl.YarnClientImpl: Submitted application application_1759553191529_0001
2025-10-04 04:51:14,012 INFO mapreduce.Job: The url to track the job: http://resourcemanager:8088/proxy/application_1759553191529_0001/
2025-10-04 04:51:14,012 INFO mapreduce.Job: Running job: job_1759553191529_0001
2025-10-04 04:51:21,139 INFO mapreduce.Job: Job job_1759553191529_0001 running in uber mode : false
2025-10-04 04:51:21,140 INFO mapreduce.Job: map 0% reduce 0%
2025-10-04 04:51:32,305 INFO mapreduce.Job: map 10% reduce 0%
2025-10-04 04:51:33,326 INFO mapreduce.Job: map 20% reduce 0%
2025-10-04 04:51:34,364 INFO mapreduce.Job: map 30% reduce 0%
2025-10-04 04:51:35,382 INFO mapreduce.Job: map 40% reduce 0%
2025-10-04 04:51:37,429 INFO mapreduce.Job: map 50% reduce 0%
2025-10-04 04:51:41,485 INFO mapreduce.Job: map 60% reduce 0%
2025-10-04 04:51:42,493 INFO mapreduce.Job: map 80% reduce 0%
2025-10-04 04:51:43,500 INFO mapreduce.Job: map 100% reduce 0%
2025-10-04 04:51:44,506 INFO mapreduce.Job: map 100% reduce 100%
2025-10-04 04:51:45,522 INFO mapreduce.Job: Job job_1759553191529_0001 completed successfully
2025-10-04 04:51:45,641 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=62
FILE: Number of bytes written=3060677
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2640
HDFS: Number of bytes written=215
HDFS: Number of read operations=45
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Rack-local map tasks=10
Total time spent by all maps in occupied slots (ms)=374020
Total time spent by all reduces in occupied slots (ms)=75464
Total time spent by all map tasks (ms)=93505
Total time spent by all reduce tasks (ms)=9433
Total vcore-milliseconds taken by all map tasks=93505
Total vcore-milliseconds taken by all reduce tasks=9433
Total megabyte-milliseconds taken by all map tasks=382996480
Total megabyte-milliseconds taken by all reduce tasks=77275136
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=250
Input split bytes=1460
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=250
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=582
CPU time spent (ms)=4280
Physical memory (bytes) snapshot=3847557120
Virtual memory (bytes) snapshot=60245340160
Total committed heap usage (bytes)=4464836608
Peak Map Physical memory (bytes)=381763584
Peak Map Virtual memory (bytes)=5181583360
Peak Reduce Physical memory (bytes)=282779648
Peak Reduce Virtual memory (bytes)=8527212544
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 33.3 seconds
Estimated value of Pi is 3.17333333333333333333
6. Accessing the Web Interfaces:
-
HDFS Namenode:http://localhost:9870
Expected Output:
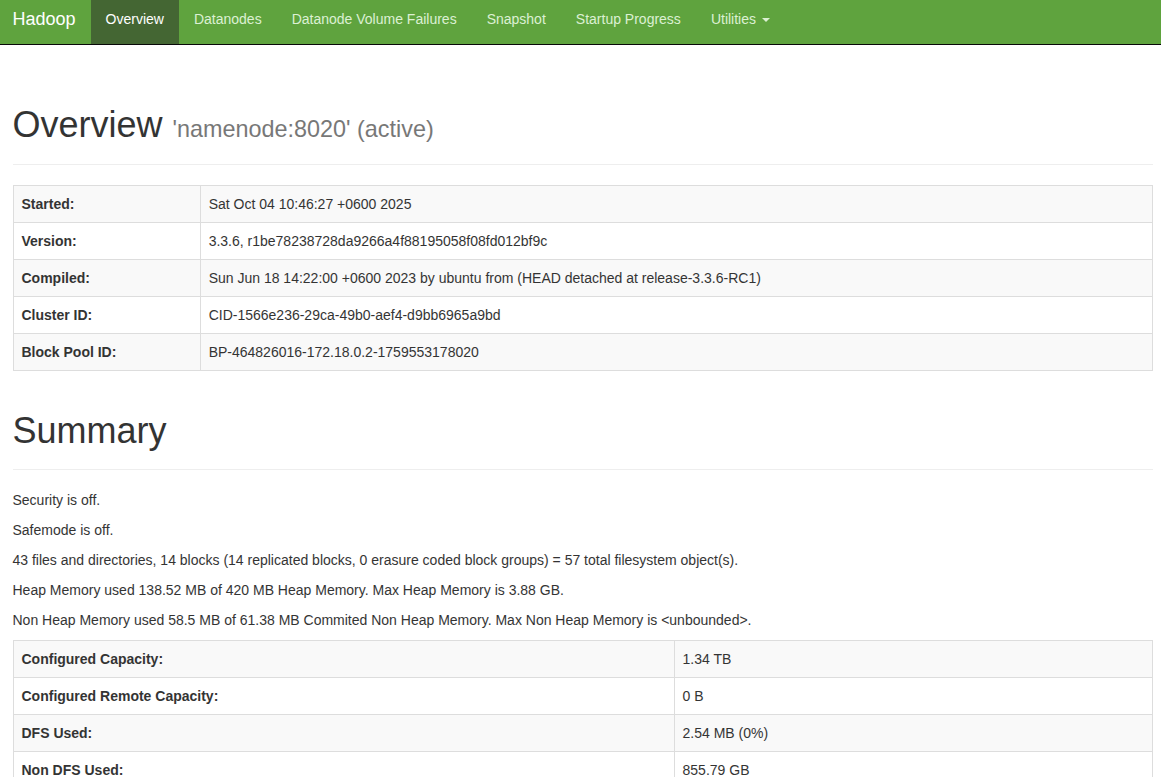
-
ResourceManager:http://localhost:8088
Expected Output:
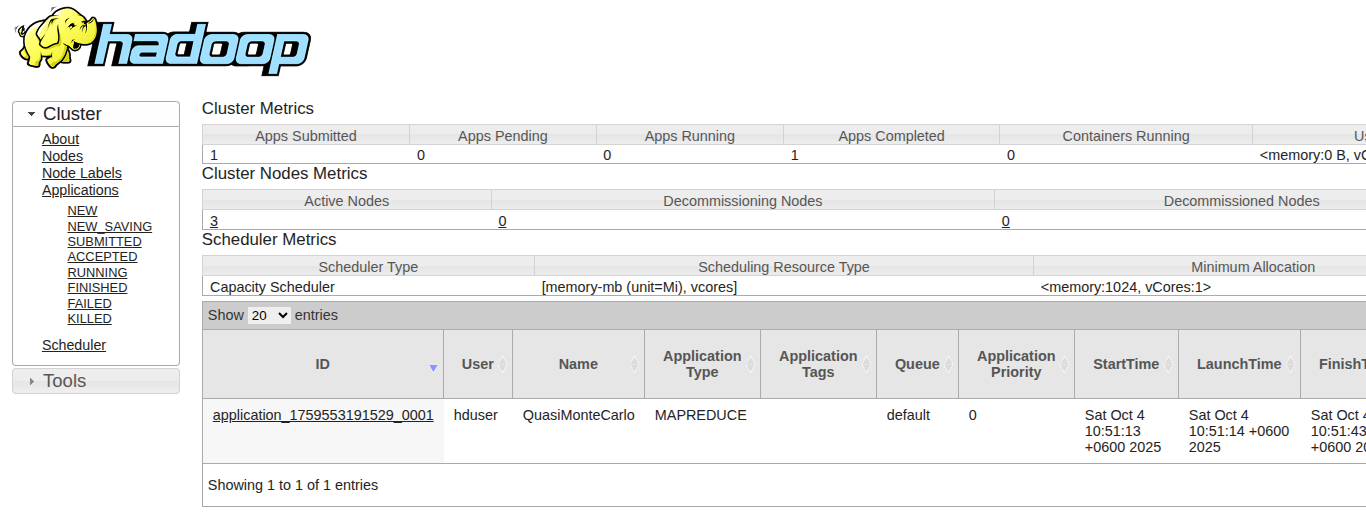
-
History Server:http://localhost:8188
Expected Output:
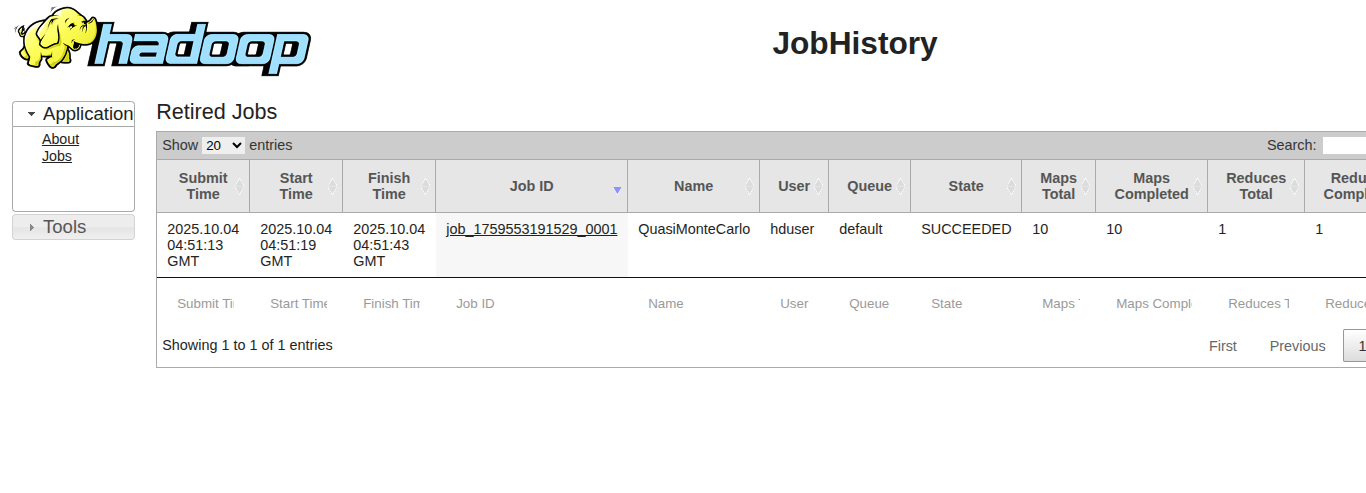
-
NodeManager1:http://localhost:8042
Expected Output:
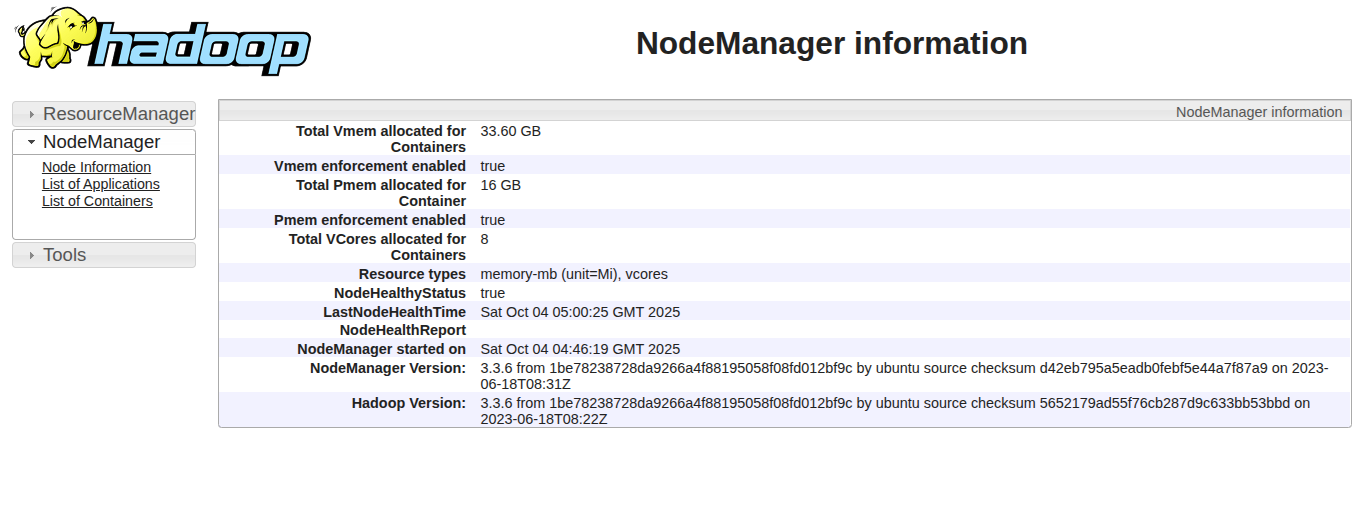
- NodeManager2:http://localhost:8043
- NodeManager3:http://localhost:8044
Type exit to return command prompt.
7. Shutdown Cluster :
The cluster can be shut down with the following commmands
docker compose down
The commands and output should look like the following.
hadoop$ docker compose down
[+] Running 10/10
✔ Container datanode1 Removed 5.8s
✔ Container nodemanager3 Removed 5.8s
✔ Container datanode2 Removed 5.8s
✔ Container nodemanager2 Removed 5.8s
✔ Container historyserver Removed 5.8s
✔ Container datanode3 Removed 5.8s
✔ Container nodemanager1 Removed 5.8s
✔ Container resourcemanager Removed 1.9s
✔ Container namenode Removed 2.2s
✔ Network hadoop-cluster-net Removed 0.3s
Thanks

Image:freepik