Hadoop 3.4.1 Deployment on Docker
Docker is a powerful open-source platform that empowers developers to sealessly build, share, and run
applications within lightweight, portable containers. This elegant approch to containerization
ensures consistency accross various environments.
To deploy a Hadoop cluster, we can leverage this very technology. The process begins by pulling a pre-configured Hadoop image from a repository. For this deployment, we will utilize the trusted apache/hadoop:3.4.1 image from Docker Hub. This version represents the latest stable release, providing a robust and reliable foundation for our cluster, which we will then tailor by specifying our required configurations.
For users on the Windows operating system, there are two primary and elegant pathways to harness the power of Docker:
1. Docker Desktop with WSL 2 This is the recommended and most seamless method for modern Windows development. Docker Desktop is a comprehensive, user-friendly application that seamlessly integrates the Docker Engine, command-line interface (CLI), and all necessary companion tools into a single, intuitive experience. It achieves its remarkable performance and Linux compatibility by running on the Windows Subsystem for Linux 2 (WSL 2), the latest and most advanced architecture for running a Linux kernel directly on Windows.
2. Docker on Windows Server Designed for production environments, this approach allows Windows Server users to install and run the Docker Engine natively. This method is tailored for operating Windows containers directly on the Windows Server operating system, bypassing the need for the Docker Desktop application interface for a more integrated server-side operation.
For the purpose of setting up our Hadoop cluster, which is inherently a Linux-based ecosystem, we will be utilizing a Linux environment. Specifically, we will perform the deployment within a Linux Ubuntu system to ensure full compatibility and optimal performance.
Create a new folder, say "hadoop" which contains a folder namely "config" and a file "docker-compose.yaml". The Config contains the
following 6 files
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
- capacity-scheduler.xml.
- log4j.properties
hadoop
├── config
│ ├── capacity-scheduler.xml
│ ├── core-site.xml
│ ├── hdfs-site.xml
│ ├── log4j.properties
│ ├── mapred-site.xml
│ └── yarn-site.xml
└── docker-compose.yaml
1. Preparation of files of config folder and docker-compose.yaml files.
1. Copy the following codes and paste them into the core-site.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
</property>
</configuration>
2. Copy the following codes and paste them into the hdfs-site.xml file.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/hadoop-root/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/hadoop-root/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3. Copy the following codes and paste them into the yarn-site.xml file.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>resourcemanager</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>600</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://historyserver:19888/jobhistory/logs</value>
</property>
</configuration>
4. Copy the following codes and paste them into the mapred-site.xml file.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>historyserver:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>historyserver:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop</value>
</property>
</configuration>
5. Copy the following codes and paste them into the capacity-scheduler-site.xml file.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
</property>
</configuration>
6. Copy the following codes and paste them into the log4j.properties file.
hadoop.root.logger=INFO,console
hadoop.log.dir=.
hadoop.log.file=hadoop.log
# Define the root logger to the system property "hadoop.root.logger".
log4j.rootLogger=${hadoop.root.logger}
# Logging Threshold
log4j.threshold=ALL
# Null Appender
log4j.appender.NullAppender=org.apache.log4j.varia.NullAppender
#
# Rolling File Appender - cap space usage at 5gb.
#
hadoop.log.maxfilesize=256MB
hadoop.log.maxbackupindex=20
log4j.appender.RFA=org.apache.log4j.RollingFileAppender
log4j.appender.RFA.File=${hadoop.log.dir}/${hadoop.log.file}
log4j.appender.RFA.MaxFileSize=${hadoop.log.maxfilesize}
log4j.appender.RFA.MaxBackupIndex=${hadoop.log.maxbackupindex}
log4j.appender.RFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
#log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n
#
# Daily Rolling File Appender
#
log4j.appender.DRFA=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFA.File=${hadoop.log.dir}/${hadoop.log.file}
# Rollover at midnight
log4j.appender.DRFA.DatePattern=.yyyy-MM-dd
log4j.appender.DRFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
#log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
#
#Security appender
#
hadoop.security.logger=INFO,NullAppender
hadoop.security.log.maxfilesize=256MB
hadoop.security.log.maxbackupindex=20
log4j.category.SecurityLogger=${hadoop.security.logger}
hadoop.security.log.file=SecurityAuth-${user.name}.audit
log4j.appender.RFAS=org.apache.log4j.RollingFileAppender
log4j.appender.RFAS.File=${hadoop.log.dir}/${hadoop.security.log.file}
log4j.appender.RFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.RFAS.MaxFileSize=${hadoop.security.log.maxfilesize}
log4j.appender.RFAS.MaxBackupIndex=${hadoop.security.log.maxbackupindex}
#
# Daily Rolling Security appender
#
log4j.appender.DRFAS=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFAS.File=${hadoop.log.dir}/${hadoop.security.log.file}
log4j.appender.DRFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.DRFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.DRFAS.DatePattern=.yyyy-MM-dd
#
# hadoop configuration logging
#
#
# hdfs audit logging
#
hdfs.audit.logger=INFO,NullAppender
hdfs.audit.log.maxfilesize=256MB
hdfs.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=${hdfs.audit.logger}
log4j.additivity.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=false
log4j.appender.RFAAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.RFAAUDIT.File=${hadoop.log.dir}/hdfs-audit.log
log4j.appender.RFAAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.RFAAUDIT.MaxFileSize=${hdfs.audit.log.maxfilesize}
log4j.appender.RFAAUDIT.MaxBackupIndex=${hdfs.audit.log.maxbackupindex}
#
# NameNode metrics logging.
# The default is to retain two namenode-metrics.log files up to 64MB each.
#
namenode.metrics.logger=INFO,NullAppender
log4j.logger.NameNodeMetricsLog=${namenode.metrics.logger}
log4j.additivity.NameNodeMetricsLog=false
log4j.appender.NNMETRICSRFA=org.apache.log4j.RollingFileAppender
log4j.appender.NNMETRICSRFA.File=${hadoop.log.dir}/namenode-metrics.log
log4j.appender.NNMETRICSRFA.layout=org.apache.log4j.PatternLayout
log4j.appender.NNMETRICSRFA.layout.ConversionPattern=%d{ISO8601} %m%n
log4j.appender.NNMETRICSRFA.MaxBackupIndex=1
log4j.appender.NNMETRICSRFA.MaxFileSize=64MB
#
# DataNode metrics logging.
# The default is to retain two datanode-metrics.log files up to 64MB each.
#
datanode.metrics.logger=INFO,NullAppender
log4j.logger.DataNodeMetricsLog=${datanode.metrics.logger}
log4j.additivity.DataNodeMetricsLog=false
log4j.appender.DNMETRICSRFA=org.apache.log4j.RollingFileAppender
log4j.appender.DNMETRICSRFA.File=${hadoop.log.dir}/datanode-metrics.log
log4j.appender.DNMETRICSRFA.layout=org.apache.log4j.PatternLayout
log4j.appender.DNMETRICSRFA.layout.ConversionPattern=%d{ISO8601} %m%n
log4j.appender.DNMETRICSRFA.MaxBackupIndex=1
log4j.appender.DNMETRICSRFA.MaxFileSize=64MB
# Custom Logging levels
log4j.logger.com.amazonaws.http.AmazonHttpClient=ERROR
#
# Set the ResourceManager summary log filename
yarn.server.resourcemanager.appsummary.log.file=rm-appsummary.log
# Set the ResourceManager summary log level and appender
yarn.server.resourcemanager.appsummary.logger=${hadoop.root.logger}
#yarn.server.resourcemanager.appsummary.logger=INFO,RMSUMMARY
log4j.logger.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=${yarn.server.resourcemanager.appsummary.logger}
log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=false
log4j.appender.RMSUMMARY=org.apache.log4j.RollingFileAppender
log4j.appender.RMSUMMARY.File=${hadoop.log.dir}/${yarn.server.resourcemanager.appsummary.log.file}
log4j.appender.RMSUMMARY.MaxFileSize=256MB
log4j.appender.RMSUMMARY.MaxBackupIndex=20
log4j.appender.RMSUMMARY.layout=org.apache.log4j.PatternLayout
log4j.appender.RMSUMMARY.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
#
# YARN ResourceManager audit logging
#
rm.audit.logger=INFO,NullAppender
rm.audit.log.maxfilesize=256MB
rm.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.yarn.server.resourcemanager.RMAuditLogger=${rm.audit.logger}
log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager.RMAuditLogger=false
log4j.appender.RMAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.RMAUDIT.File=${hadoop.log.dir}/rm-audit.log
log4j.appender.RMAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.RMAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.RMAUDIT.MaxFileSize=${rm.audit.log.maxfilesize}
log4j.appender.RMAUDIT.MaxBackupIndex=${rm.audit.log.maxbackupindex}
#
# YARN NodeManager audit logging
#
nm.audit.logger=INFO,NullAppender
nm.audit.log.maxfilesize=256MB
nm.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.yarn.server.nodemanager.NMAuditLogger=${nm.audit.logger}
log4j.additivity.org.apache.hadoop.yarn.server.nodemanager.NMAuditLogger=false
log4j.appender.NMAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.NMAUDIT.File=${hadoop.log.dir}/nm-audit.log
log4j.appender.NMAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.NMAUDIT.layout.ConversionPattern=%d{ISO8601}%p %c{2}: %m%n
log4j.appender.NMAUDIT.MaxFileSize=${nm.audit.log.maxfilesize}
log4j.appender.NMAUDIT.MaxBackupIndex=${nm.audit.log.maxbackupindex}
#
# YARN Router audit logging
#
router.audit.logger=INFO,NullAppender
router.audit.log.maxfilesize=256MB
router.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.yarn.server.router.RouterAuditLogger=${router.audit.logger}
log4j.additivity.org.apache.hadoop.yarn.server.router.RouterAuditLogger=false
log4j.appender.ROUTERAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.ROUTERAUDIT.File=${hadoop.log.dir}/router-audit.log
log4j.appender.ROUTERAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.ROUTERAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.ROUTERAUDIT.MaxFileSize=${router.audit.log.maxfilesize}
log4j.appender.ROUTERAUDIT.MaxBackupIndex=${router.audit.log.maxbackupindex}
# Appender for viewing information for errors and warnings
yarn.ewma.cleanupInterval=300
yarn.ewma.messageAgeLimitSeconds=86400
yarn.ewma.maxUniqueMessages=250
log4j.appender.EWMA=org.apache.hadoop.yarn.util.Log4jWarningErrorMetricsAppender
log4j.appender.EWMA.cleanupInterval=${yarn.ewma.cleanupInterval}
log4j.appender.EWMA.messageAgeLimitSeconds=${yarn.ewma.messageAgeLimitSeconds}
log4j.appender.EWMA.maxUniqueMessages=${yarn.ewma.maxUniqueMessages}
# Log levels of third-party libraries
log4j.logger.org.apache.commons.beanutils=WARN
docker-compose.yaml
Copy the following codes and paste them into the docker-compose.yaml file.
services:
namenode:
image: apache/hadoop:3.4.1
hostname: namenode
container_name: namenode
volumes:
- ./config:/opt/hadoop/etc/hadoop
command: >
bash -c "
mkdir -p /opt/hadoop/hadoop-root/dfs/name &&
if [ ! -f /opt/hadoop/hadoop-root/dfs/name/current/VERSION ]; then
echo 'Formatting NameNode...' &&
hdfs namenode -format -force;
fi &&
hdfs namenode
"
ports:
- 9870:9870 # HDFS namenode Web UI
- 8020:8020 # HDFS RPC port (client connections)
networks:
- net
datanode1:
image: apache/hadoop:3.4.1
hostname: datanode1
container_name: datanode1
volumes:
- ./config:/opt/hadoop/etc/hadoop
command: >
bash -c "
mkdir -p /opt/hadoop/hadoop-root/dfs/data &&
hdfs datanode
"
networks:
- net
depends_on:
- namenode
datanode2:
image: apache/hadoop:3.4.1
hostname: datanode2
container_name: datanode2
volumes:
- ./config:/opt/hadoop/etc/hadoop
command: >
bash -c "
mkdir -p /opt/hadoop/hadoop-root/dfs/data &&
hdfs datanode
"
networks:
- net
depends_on:
- namenode
resourcemanager:
image: apache/hadoop:3.4.1
hostname: resourcemanager
container_name: resourcemanager
volumes:
- ./config:/opt/hadoop/etc/hadoop
command: ["yarn", "resourcemanager"]
ports:
- 8088:8088 # YARN ResourceManager Web UI
networks:
- net
depends_on:
- namenode
- datanode1
- datanode2
nodemanager:
image: apache/hadoop:3.4.1
hostname: nodemanager
container_name: nodemanager
volumes:
- ./config:/opt/hadoop/etc/hadoop
command: ["yarn", "nodemanager"]
networks:
- net
depends_on:
- resourcemanager
historyserver:
image: apache/hadoop:3.4.1
hostname: historyserver
container_name: historyserver
volumes:
- ./config:/opt/hadoop/etc/hadoop
command: ["mapred","historyserver"]
ports:
- 19888:19888 # Mapreduce History Server Web UI
networks:
- net
depends_on:
- resourcemanager
networks:
net:
driver: bridge
2: Run the docker containers
Now, run the docker containers using docker-compose.
docker compose up -d
You should see these services getting started and the following outputs
~/hadoop$ docker compose up -d
[+] Running 28/28
✔ nodemanager Pulled 395.7s
✔ namenode Pulled 395.6s
✔ historyserver Pulled 395.6s
✔ datanode2 Pulled 395.4s
✔ datanode1 Pulled 395.5s
✔ resourcemanager Pulled 395.5s
[+] Running 7/7
✔ Network hadoop_net Created 0.3s
✔ Container namenode Started 6.4s
✔ Container datanode1 Started 6.6s
✔ Container datanode2 Started 6.8s
✔ Container resourcemanager Started 6.6s
✔ Container historyserver Started 7.6s
✔ Container nodemanager Started 7.2s
3: Accessing the Cluster.
Login into a node:
Can login into any node by specifying the container like:
docker exec -it namenode /bin/bash
To enter the namenode, type commands that look like the following.
~/hadoop$ docker exec -it namenode /bin/bash
Expected Output:
bash-4.2$
Running an example Job(Pi job)
bash-4.2$ yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.1.jar pi 10 15
The output should look like:
Number of Maps = 10
Samples per Map = 15
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
2025-09-24 04:30:52,575 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at resourcemanager/172.18.0.5:8032
2025-09-24 04:30:53,089 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1758688183790_0001
2025-09-24 04:30:53,391 INFO input.FileInputFormat: Total input files to process : 10
2025-09-24 04:30:53,917 INFO mapreduce.JobSubmitter: number of splits:10
2025-09-24 04:30:54,680 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1758688183790_0001
2025-09-24 04:30:54,680 INFO mapreduce.JobSubmitter: Executing with tokens: []
2025-09-24 04:30:54,959 INFO conf.Configuration: resource-types.xml not found
2025-09-24 04:30:54,960 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2025-09-24 04:30:55,524 INFO impl.YarnClientImpl: Submitted application application_1758688183790_0001
2025-09-24 04:30:55,620 INFO mapreduce.Job: The url to track the job: http://resourcemanager:8088/proxy/application_1758688183790_0001/
2025-09-24 04:30:55,621 INFO mapreduce.Job: Running job: job_1758688183790_0001
2025-09-24 04:31:03,779 INFO mapreduce.Job: Job job_1758688183790_0001 running in uber mode : false
2025-09-24 04:31:03,780 INFO mapreduce.Job: map 0% reduce 0%
2025-09-24 04:31:09,905 INFO mapreduce.Job: map 10% reduce 0%
2025-09-24 04:31:11,943 INFO mapreduce.Job: map 20% reduce 0%
2025-09-24 04:31:13,985 INFO mapreduce.Job: map 30% reduce 0%
2025-09-24 04:31:16,018 INFO mapreduce.Job: map 40% reduce 0%
2025-09-24 04:31:17,031 INFO mapreduce.Job: map 60% reduce 0%
2025-09-24 04:31:18,051 INFO mapreduce.Job: map 70% reduce 0%
2025-09-24 04:31:20,075 INFO mapreduce.Job: map 80% reduce 0%
2025-09-24 04:31:21,081 INFO mapreduce.Job: map 90% reduce 0%
2025-09-24 04:31:22,088 INFO mapreduce.Job: map 100% reduce 0%
2025-09-24 04:31:23,095 INFO mapreduce.Job: map 100% reduce 100%
2025-09-24 04:31:24,115 INFO mapreduce.Job: Job job_1758688183790_0001 completed successfully
2025-09-24 04:31:24,272 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=3412306
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2650
HDFS: Number of bytes written=215
HDFS: Number of read operations=45
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Rack-local map tasks=10
Total time spent by all maps in occupied slots (ms)=48230
Total time spent by all reduces in occupied slots (ms)=8862
Total time spent by all map tasks (ms)=48230
Total time spent by all reduce tasks (ms)=8862
Total vcore-milliseconds taken by all map tasks=48230
Total vcore-milliseconds taken by all reduce tasks=8862
Total megabyte-milliseconds taken by all map tasks=49387520
Total megabyte-milliseconds taken by all reduce tasks=9074688
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=280
Input split bytes=1470
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=280
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=1371
CPU time spent (ms)=5680
Physical memory (bytes) snapshot=3028217856
Virtual memory (bytes) snapshot=29256884224
Total committed heap usage (bytes)=3539468288
Peak Map Physical memory (bytes)=367251456
Peak Map Virtual memory (bytes)=2662064128
Peak Reduce Physical memory (bytes)=213344256
Peak Reduce Virtual memory (bytes)=2664308736
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 31.865 seconds
Estimated value of Pi is 3.17333333333333333333
4. Accessing the Web Interfaces:
-
HDFS Namenode:http://localhost:9870
Expected Output:
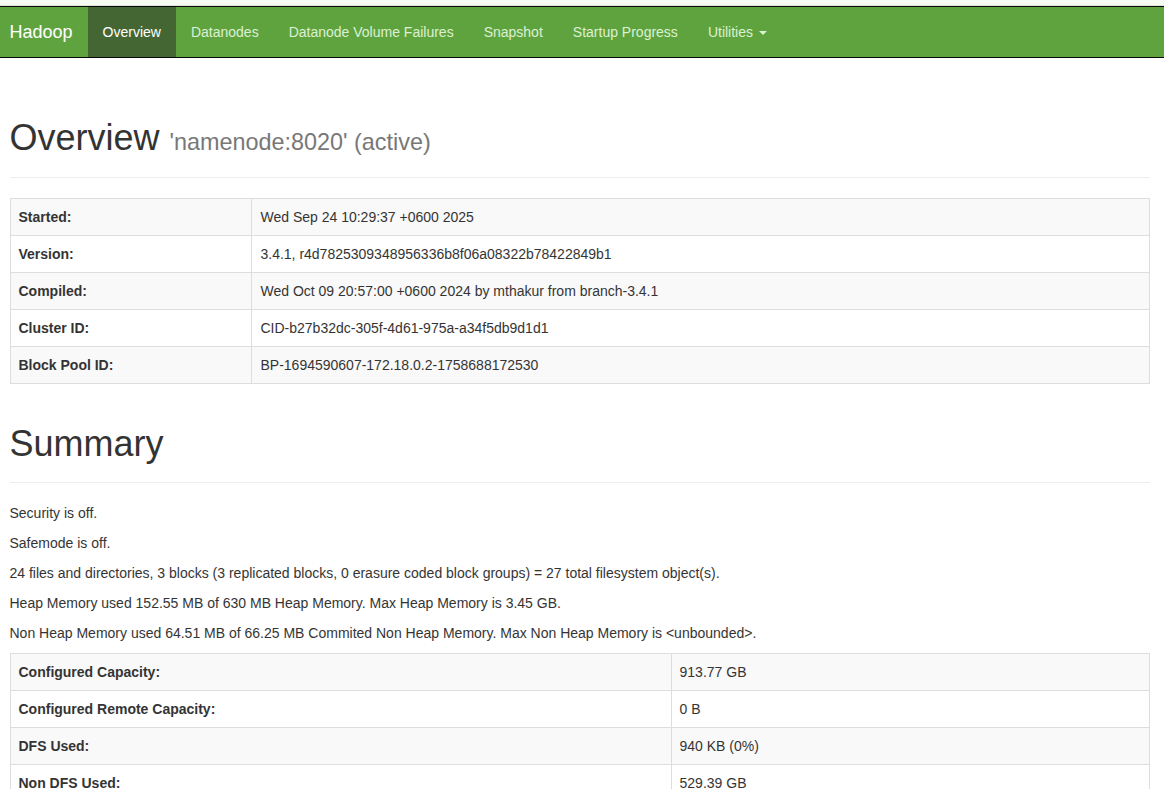
-
YARN ResourceManager:http://localhost:8088
Expected Output:
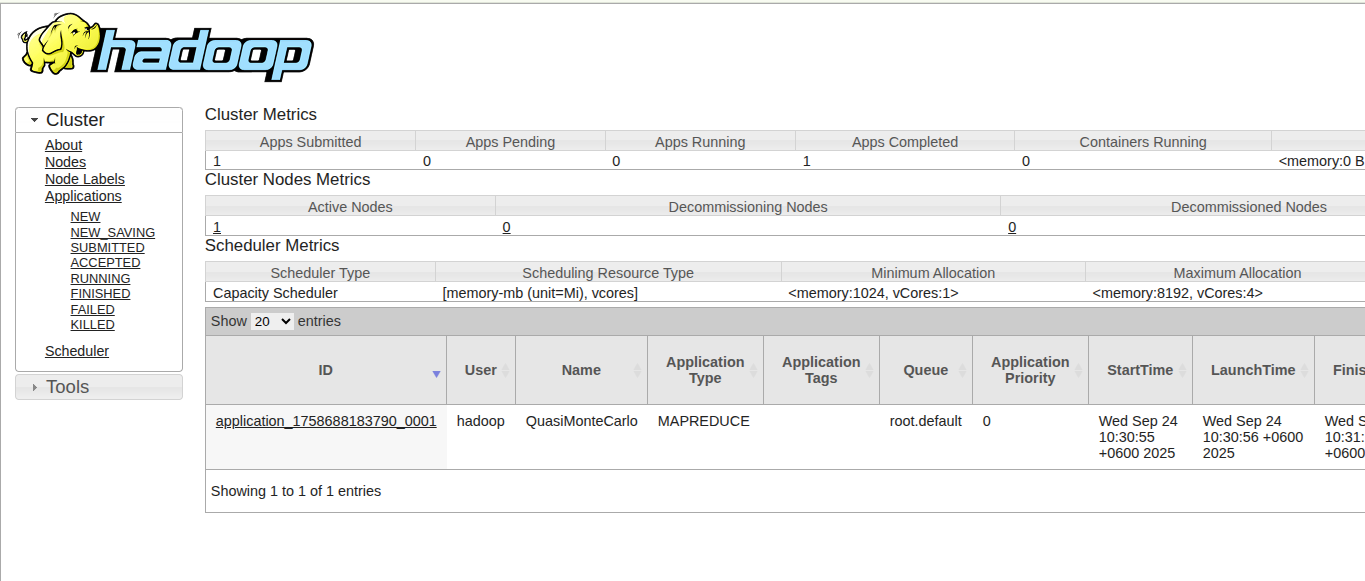
-
MapReduce History Server:http://localhost:19888
Expected Output:
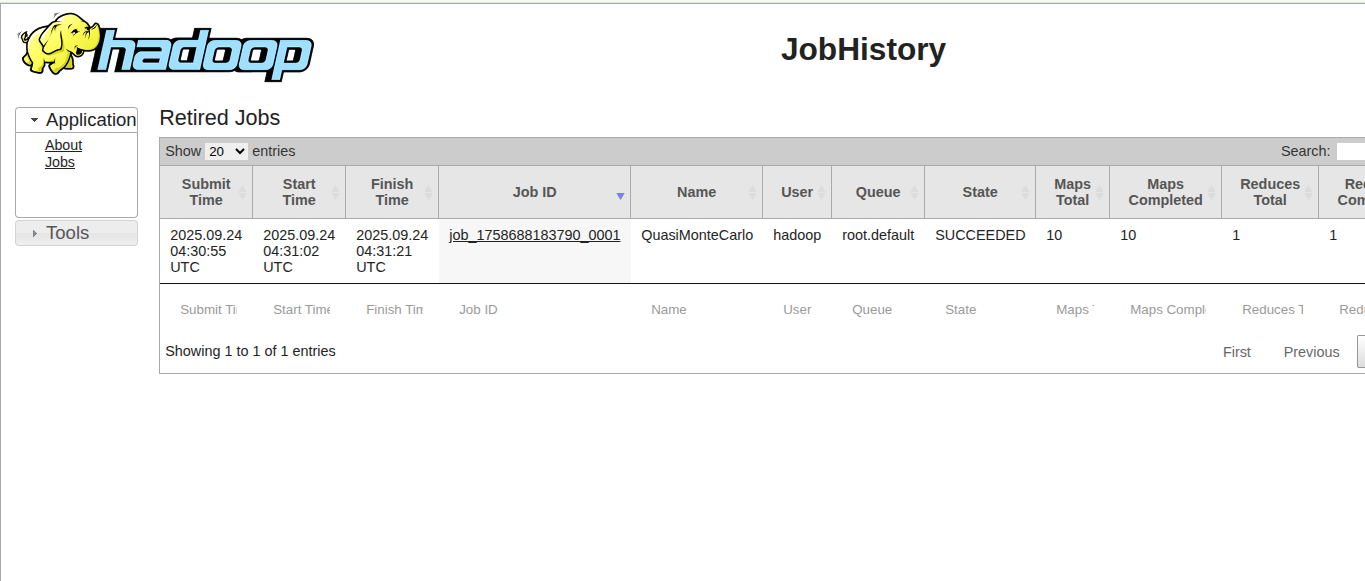
Type exit to return command prompt.
5. Shutdown Cluster :
The cluster can be shut down with the following commmands
docker compose down
The commands and output should look like the following.
~/hadoop$ docker compose down
[+] Running 7/7
✔ Container historyserver Removed 3.3s
✔ Container nodemanager Removed 3.4s
✔ Container resourcemanager Removed 1.4s
✔ Container datanode1 Removed 1.8s
✔ Container datanode2 Removed 1.7s
✔ Container namenode Removed 1.2s
✔ Network hadoop_net Removed 0.3s
Thanks

Image:freepik